Overview: Soft Muon1 uses weighted sums of Newton-Schulz iterates to approximate for I extend this approximation to by optimizing a heterogeneous polynomial basis and computing weights via Chebyshev interpolation.
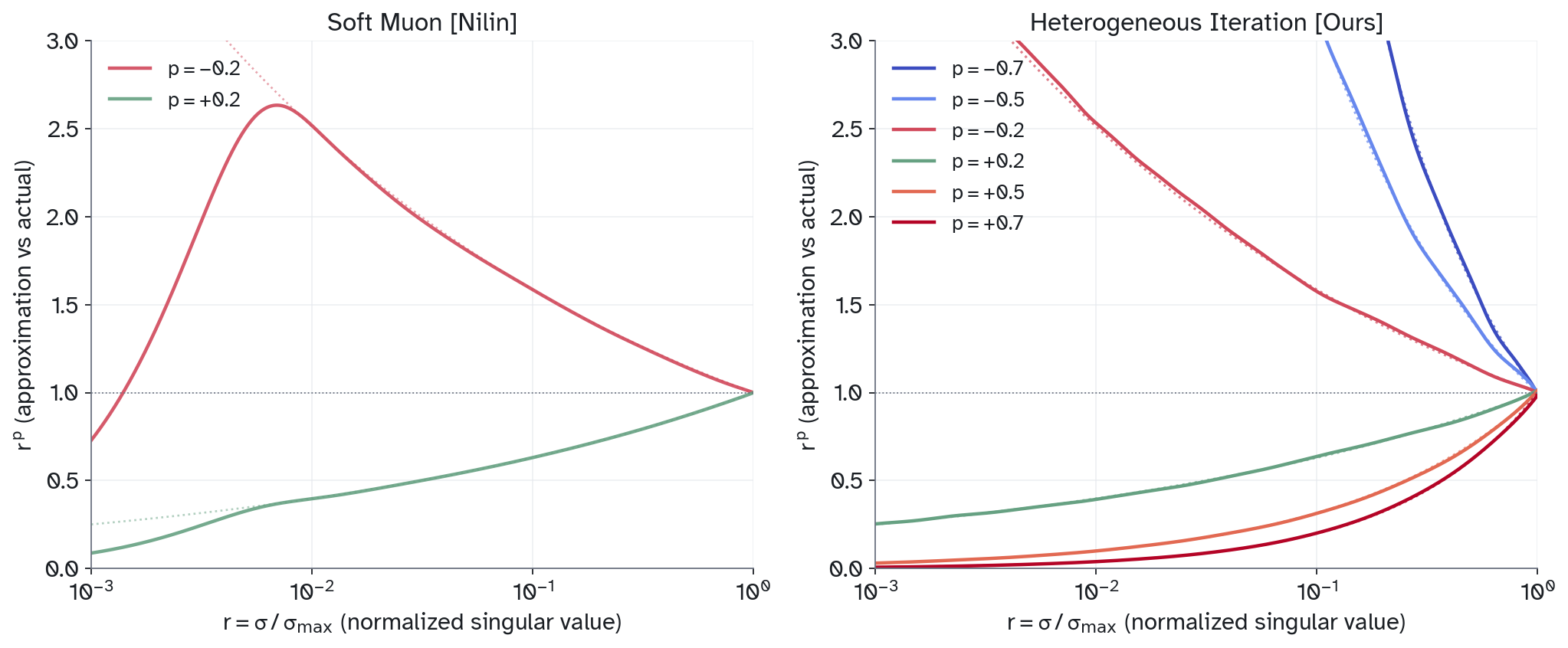
Figure 1: For any singular value we achieve error no worse than .
Let’s consider a matrix . The Muon optimizer2 uses several polynomial iterations of in order to approximate This can be seen as a special case () of the family for arbitrary powers . The full family turns out to be useful, with being used in Shampoo/SOAP3456 and showing promise in Muon-variants1789.
As shown in Soft Muon, the iterates of a polynomial sequence can be used as a linear basis for this approximation, which has the advantage of requiring only as many matmuls as the original Newton-Schulz method. Soft Muon uses a single polynomial with iterates as a basis for the approximations and .
Unlike in Soft Muon, we define 9 distinct odd quintic polynomials and weights such that
is very good on for matrices with .
Weights are fast to generate for any , requiring only a single matmul:
where is a fixed matrix and is a vector with
For additional details and the method used to search for the optimal polynomial coefficients see the code artifact in the appendix.
Input matrices must be normalized so that singular values are all . Soft Muon normalizes by the Schatten-4 norm; I recommend using the Schatten- (spectral norm) instead, which places the largest singular value at exactly 1 and gives the polynomial basis maximum resolution over the spectrum. The spectral norm can be computed cheaply via power iteration, and the final result can be rescaled by to recover the normalization-free magnitudes.
This approximation is accurate on singular values . Therefore, it works well for any initial matrix with condition number Beyond this, small get sent toward 0 rather than blowing up. This closely matches the behavior of Polar Express10 at 8 iterations, which uses an optimal heterogenous polynomial basis for .
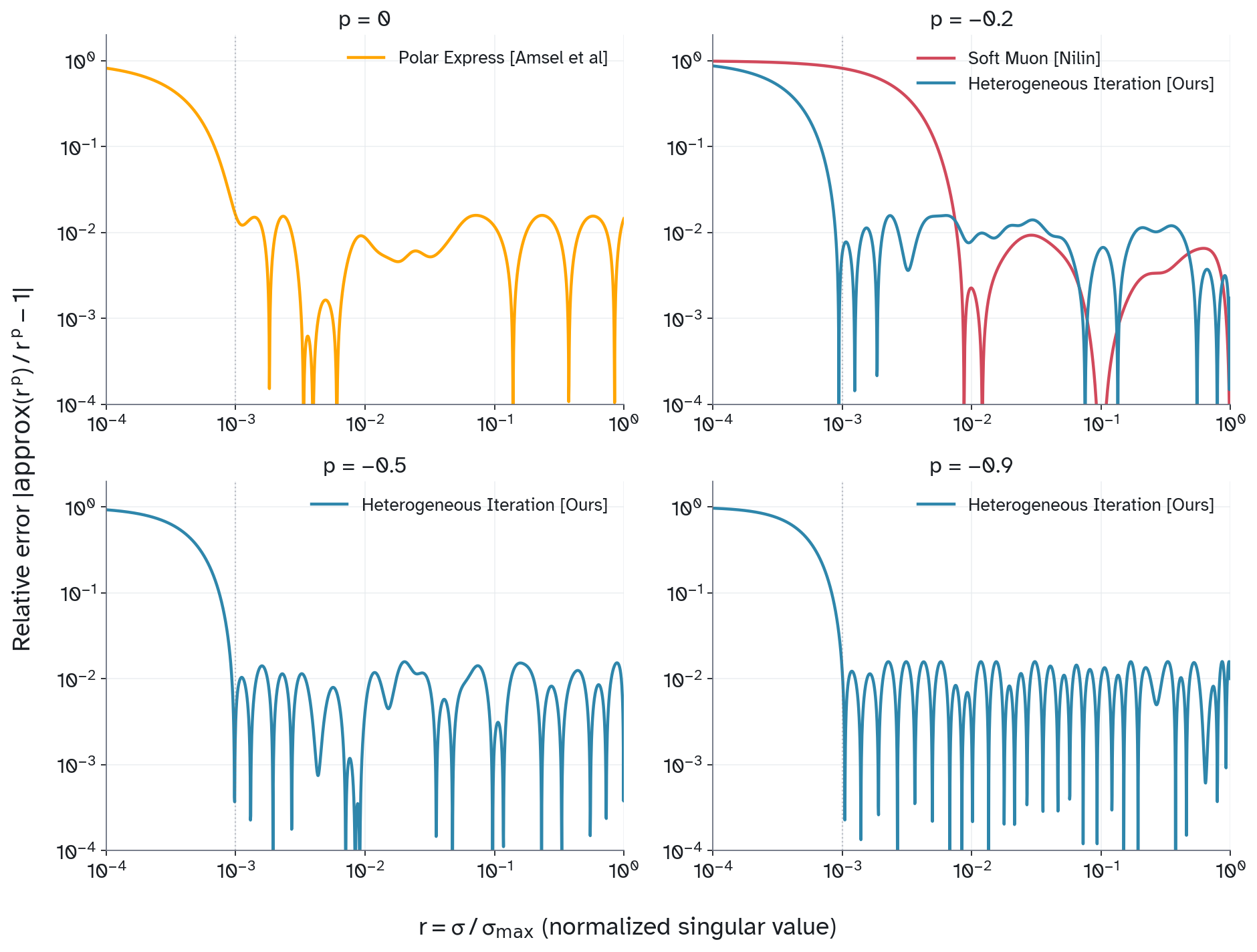
Figure 2: Approximation error of our method for , alongside comparisons to Polar express () and Soft Muon ().
Code
import torch
import numpy as np
POLYNOMIAL_COEFFS = [
(3.059785, -3.569183, 1.466139),
(2.483037, -2.035164, 0.593904),
(2.587005, -2.273627, 0.704639),
(2.532325, -2.285401, 0.721930),
(2.814393, -2.718119, 0.918760),
(2.574423, -2.244986, 0.670563),
(2.420254, -2.053210, 0.632956),
(3.096905, -3.325603, 1.228698),
]
ALPHA = np.array([
[ -0.342922, 1.596394, -0.351650, 0.035747, 0.010101, 0.013627, 0.011582, -0.006495, 0.003221, -0.005116, -0.010389],
[ -0.922227, 1.685416, -0.956170, 0.295072, -0.055173, -0.012259, 0.002832, -0.002589, -0.002554, -0.006862, 0.012596],
[ -2.066104, 3.685898, -2.420166, 1.082506, -0.344673, 0.092675, -0.032001, 0.008406, 0.013576, 0.004359, -0.009345],
[ -4.661157, 8.342554, -5.843200, 3.137332, -1.305372, 0.423156, -0.095726, 0.014060, -0.017478, 0.012561, -0.000413],
[ -10.383074, 18.875298, -14.077936, 8.559896, -4.276353, 1.786916, -0.637048, 0.187610, -0.030537, -0.010511, 0.005912],
[ -22.714826, 41.762294, -32.381749, 21.153520, -11.691129, 5.512954, -2.238141, 0.790077, -0.244064, 0.063162, -0.009966],
[ -44.136919, 81.881166, -65.290701, 44.713397, -26.345783, 13.425638, -5.956984, 2.302977, -0.755408, 0.189607, -0.026751],
[ 6.535768, -11.015945, 6.364808, -2.004427, -0.416101, 1.052051, -0.804394, 0.387948, -0.112107, 0.009609, 0.003072],
[ 79.795883, -146.994699, 115.107893, -77.081238, 44.497143, -22.325210, 9.771873, -3.689135, 1.144857, -0.258366, 0.031091],
])
P_MAX = 0.9
def compute_weights(p):
tau = p / P_MAX
T = np.array([np.cos(l * np.arccos(tau)) for l in range(ALPHA.shape[1])])
return ALPHA @ T
def apply(X, coeffs, weights):
transposed = X.size(-2) > X.size(-1)
if transposed: X = X.mT
iterates = [X]
for a, b, c in coeffs:
Xk = iterates[-1]
XtX = Xk.mT @ Xk
iterates.append(a * Xk + b * (Xk @ XtX) + c * (Xk @ (XtX @ XtX)))
result = sum(w * Xi for w, Xi in zip(weights, iterates))
return result.mT if transposed else result
def matrix_power(G, p):
# Computes UΣ^pV^T for G = UΣV^T
assert -P_MAX <= p <= P_MAX
sigma_max = torch.linalg.norm(G, ord=2) # can use power iter
X = G / (sigma_max + 1e-6)
w = torch.tensor(compute_weights(p))
return apply(X, POLYNOMIAL_COEFFS, w) * (sigma_max ** p)Related work
Soft Muon1 is the primary inspiration. It uses the iterates of a single polynomial as a basis, and gives distinct weights for and . The key innovation in this post is to optimize a heterogenous basis—i.e. uses a new polynomial per iterate.
DynMuon7 decomposes and approximates via an order-2 Taylor expansion. Though simple and cheap, the approximation quality is limited:
| κ | p=-0.2 | p=0.1 | p=0.2 | p=0.5 |
|---|---|---|---|---|
| 2 | 25% | 15% | 31% | 90% |
| 100 | 49% | 31% | 63% | 157% |
| 1000 | 63% | 43% | 87% | 194% |
HTMuon8 uses the same decomposition as DynMuon but computes via coupled Denman-Beavers iteration (cubic convergence). Their approach is scale-free and achieves arbitrary precision, but operates on (condition ), requiring many iterations to converge for ill-conditioned matrices. The available values of are restricted to dyadic fractions ; in practice they only use .
SMuon11 proposes a Taylor expansion centered around the polar factor, . This is better-conditioned than DynMuon’s expansion (centered at ) since the polar factor is already close to the target. The below table summarizes convergence error for various :
| κ | p=0.1 | p=0.2 | p=0.5 | p=-0.2 | p=-0.5 |
|---|---|---|---|---|---|
| 10 | 1.5% | 2.5% | 2.8% | 4.7% | 16% |
| 100 | 9.2% | 15% | 17% | 24% | 60% |
| 1000 | 20% | 33% | 33% | 45% | 85% |
Streaming exponential iteration12 as articulated by Jianlin Su approximates SVD via a streaming power iteration (, , ), and allows us to manipulate directly. This allows arbitrary spectral transformations and is extremely powerful, but requires stateful streaming and a QR solve per step.
Freon9 uses rational approximations with Remez-optimal coefficients instead of polynomial iterations, avoiding the condition-squaring problem via block-QR. This converges quickly and can handle equal to any rational power . Instead of polynomial matmuls per iterate, this method requires a rational function evaluation and QR factorization per step.
Various Shampoo/SOAP implementations compute matrix powers or on SPD matrices by maintaining a factorization of into an eigenbasis and per-component scaling, update either via full eigen-decomposition4 or via a cheaper QR-based eigenbasis approximation.63
In future work I would like to characterize how many polynomial iterates are needed to expand the range beyond or below ; as well as compare the method in this blog to the well-known coupled iterative matrix-root algorithms for
Appendix
Reproduction for finding polynomial coefficients + the Chebyshev approx for the weights. Rough idea: try to maximize the span of the basis for and quintic degree- polynomials . To do this, use CMA-ES with an optimization target of the max relative error across 10 values of on .
The target function () is analytic in . Linear maps preserve analyticity so it turns out that the weights for our basis can be fitted via low-degree polynomials. I found approximation quality plateaus by degree-10 using Chebyshev polynomials. There are 9 iterates in total, giving weight parameters.
import numpy as np
from scipy.optimize import linprog
import cma
import time
EPS = 1e-3
P_MAX = 0.9
N_GRID = 2000
K = 8
L_CHEB = 10
R_GRID = np.geomspace(EPS, 1.0, N_GRID)
P_EVAL = np.array([-0.9, -0.7, -0.5, -0.3, -0.1, 0.1, 0.3, 0.5, 0.7, 0.9])
TARGETS = np.column_stack([R_GRID ** p for p in P_EVAL])
def build_basis(coeffs, r_grid):
psi = np.zeros((K + 1, len(r_grid)))
psi[0] = r_grid
for k in range(K):
a, b, c = coeffs[k]
x = psi[k]
psi[k + 1] = a * x + b * x**3 + c * x**5
return psi
def params_to_coeffs(params):
coeffs = []
idx = 0
# layers 0-4
for k in range(5):
a, b, d = params[idx], params[idx+1], params[idx+2]
coeffs.append((a, b, d - a - b))
idx += 3
# layers 5-7: q(1) = 1, same constraint as Newton-Schulz/Polar Express
for k in range(5, 8):
a, b = params[idx], params[idx+1]
coeffs.append((a, b, 1.0 - a - b))
idx += 2
return coeffs
def objective(params):
coeffs = params_to_coeffs(params)
psi = build_basis(coeffs, R_GRID)
if not np.all(np.isfinite(psi)):
return 10.0
A = psi.T
W, _, _, _ = np.linalg.lstsq(A, TARGETS, rcond=None)
max_err = np.abs((A @ W) / TARGETS - 1.0).max()
if not np.isfinite(max_err):
return 10.0
penalty = 0.0
for k in range(K):
penalty += 50.0 * max(0, psi[k+1].max() - 1.2)
penalty += 50.0 * max(0, -psi[k+1].min() - 0.01)
col_norms = np.linalg.norm(A, axis=0)
col_norms[col_norms == 0] = 1.0
sv = np.linalg.svd(A / col_norms, compute_uv=False)
return max_err + 1e-3 * np.log(sv[0] / max(sv[-1], 1e-15)) + penalty
def solve_joint_lp(coeffs):
r_grid = np.geomspace(EPS, 1.0, 500)
p_grid = np.linspace(-P_MAX, P_MAX, 50)
p_grid = p_grid[np.abs(p_grid) > 0.01]
psi = build_basis(coeffs, r_grid)
n_r, n_p = len(r_grid), len(p_grid)
L1 = L_CHEB + 1
n_alpha = (K + 1) * L1
tau = p_grid / P_MAX
T_vals = np.cos(np.outer(np.arange(L1), np.arccos(tau)))
A_coeff = np.zeros((n_r * n_p, n_alpha))
for j in range(n_p):
target_j = r_grid ** p_grid[j]
for k in range(K + 1):
for l in range(L1):
A_coeff[j*n_r:(j+1)*n_r, k*L1 + l] = T_vals[l, j] * psi[k] / target_j
n_vars = n_alpha + 1
c_obj = np.zeros(n_vars)
c_obj[-1] = 1.0
nc = n_r * n_p
A_ub = np.zeros((2 * nc, n_vars))
b_ub = np.zeros(2 * nc)
A_ub[:nc, :n_alpha] = A_coeff
A_ub[:nc, -1] = -1.0
b_ub[:nc] = 1.0
A_ub[nc:, :n_alpha] = -A_coeff
A_ub[nc:, -1] = -1.0
b_ub[nc:] = -1.0
bounds = [(None, None)] * n_alpha + [(0, None)]
res = linprog(c_obj, A_ub=A_ub, b_ub=b_ub, bounds=bounds, method='highs')
assert res.success, res.message
return res.x[:n_alpha].reshape(K + 1, L1), res.x[-1]
if __name__ == '__main__':
# Step 1: CMA-ES
print("Step 1: CMA-ES (21 params, ~90s)")
x0 = np.array([
3.0, -3.5, 0.96, 2.5, -2.0, 1.04, 2.6, -2.3, 1.02,
2.5, -2.3, 0.97, 2.8, -2.7, 1.01, 2.6, -2.2, 2.4, -2.1, 3.1, -3.3,
])
opts = {'maxiter': 1500, 'popsize': 96, 'verbose': -9, 'seed': 42,
'bounds': [[1.0, -8.0, 0.95]*5 + [1.0, -8.0]*3,
[5.0, 2.0, 1.05]*5 + [5.0, 2.0]*3]}
t0 = time.time()
es = cma.CMAEvolutionStrategy(x0.tolist(), 0.05, opts)
best_val, best_params = np.inf, x0
while not es.stop():
sols = es.ask()
vals = [objective(np.array(s)) for s in sols]
es.tell(sols, vals)
i = np.argmin(vals)
if vals[i] < best_val:
best_val, best_params = vals[i], np.array(sols[i])
coeffs = params_to_coeffs(best_params)
print(f" {time.time()-t0:.0f}s, objective={best_val:.6f}")
print("\nPOLYNOMIAL_COEFFS = [")
for a, b, c in coeffs:
print(f" ({a:.6f}, {b:.6f}, {c:.6f}),")
print("]")
# Step 2: Joint LP
print("\nStep 2: Joint LP (99 unknowns)")
t0 = time.time()
alpha, t_opt = solve_joint_lp(coeffs)
print(f" {time.time()-t0:.0f}s, max error={t_opt:.6f}")
print("\nALPHA = np.array([")
for row in alpha:
print(f" [{', '.join(f'{v:>11.6f}' for v in row)}],")
print("])")
# Verify
print("\nVerification:")
psi = build_basis(coeffs, R_GRID)
for p in [-0.9, -0.5, 0.0, 0.5, 0.9]:
tau = np.clip(p / P_MAX, -1, 1)
T = np.cos(np.arange(L_CHEB + 1) * np.arccos(tau))
w = alpha @ T
err = np.max(np.abs((psi.T @ w) / (R_GRID ** p) - 1))
print(f" p={p:+.1f}: {err:.4f}")
@misc{
srivastava2026,
author = {Varun Srivastava},
title = {Heterogeneous Iteration for Spectral Powers},
year = {2026},
url = {https://varunneal.github.io/essays/spectral-powers}
}
Footnotes
-
Nilin 2026 Contra-Muon and Soft-Muon ^ ^ ^
-
Keller Jordan et al 2024 Muon: An optimizer for hidden layers in neural networks ^
-
Lin et al. 2025 Understanding and Improving Shampoo and SOAP via Kullback-Leibler Minimization ^ ^
-
Anil et al. 2020 Scalable Second Order Optimization for Deep Learning ^ ^
-
Gupta et al. 2018 Shampoo: Preconditioned Stochastic Tensor Optimization ^
-
Vyas et al. 2024 SOAP: Improving and Stabilizing Shampoo using Adam ^ ^
-
Wu et al. 2025 DynMuon ^ ^
-
Pang et al. 2026 HTMuon: Improving Muon via Heavy-Tailed Spectral Correction ^ ^
-
Shumaylov et al. 2025 Muon is Not That Special: Random or Inverted Spectra Work Just as Well ^ ^
-
Amsel et al. 2025 The Polar Express ^
-
Massena et al. 2026 From SGD to Muon: Adaptive Optimization via Schatten-p Norms ^
-
Su 2026 A Muon implementation based on streaming exponential iteration ^